Hỗ trợ GPU cho máy chủ PowerEdge R360 & T360 nâng cao tiêu chuẩn cho các trường hợp sử dụng mới nổi
Khi chúng ta bước vào Năm mới, thị trường giải pháp AI trên nhiều ngành tiếp tục phát triển. Cụ thể, UBS dự đoán mức tăng vọt từ 2,2 tỷ USD vào năm 2022 lên 255 tỷ USD vào năm 2027 [1]. Sự tăng trưởng này không chỉ giới hạn ở các doanh nghiệp lớn; Hỗ trợ GPU trên máy chủ PowerEdge T360 và R360 mới giúp các doanh nghiệp thuộc mọi quy mô có thể tự do khám phá các trường hợp sử dụng suy luận AI cơ bản, bên cạnh khối lượng công việc nặng về đồ họa.
Chúng tôi đã thử nghiệm cả khối lượng công việc kết xuất 3D và suy luận AI trên PowerEdge R360 với một GPU NVIDIA A2 [1] để thể hiện đầy đủ các khả năng hiệu suất bổ sung.
Đạt được hiệu suất kết xuất gấp 5 lần với GPU NVIDIA A2
Trong thử nghiệm đầu tiên, chúng tôi đã sử dụng điểm chuẩn OpenData của Blender . Điểm chuẩn nguồn mở này đo lường hiệu suất hiển thị của nhiều cảnh 3D khác nhau trên CPU hoặc GPU. Chúng tôi đã đạt được hiệu suất kết xuất trên GPU tốt hơn tới 5 lần so với cùng một khối lượng công việc chỉ chạy trên CPU [1]. Kết quả là, khách hàng đạt được hiệu suất lên tới 1,70 lần trên mỗi đô la đầu tư vào GPU A2 so với CPU [2].
[1] Bạn có thể mong đợi kết quả tương tự trên PowerEdge T360 có cùng cấu hình.
Đạt hiệu suất suy luận tối đa với mức tiêu thụ CPU hạn chế
Một phần động lực đằng sau việc bổ sung hỗ trợ GPU là nhu cầu ngày càng tăng của các SMB về xử lý video và âm thanh tại chỗ, thời gian thực. Do đó, để đánh giá hiệu suất suy luận AI, chúng tôi đã cài đặt bộ công cụ DeepStream mã nguồn mở của NVIDIA (phiên bản 6.3). DeepStream chủ yếu được sử dụng để phát triển các ứng dụng thị giác AI tận dụng dữ liệu cảm biến cũng như các luồng camera và video khác nhau làm đầu vào. Những ứng dụng này có thể được sử dụng trong nhiều lĩnh vực công nghiệp khác nhau (ví dụ: hệ thống giám sát giao thông theo thời gian thực hoặc phân tích cảnh quay lối đi của cửa hàng bán lẻ). Với cùng PowerEdge R360, chúng tôi đã tiến hành suy luận trên 48 luồng trong khi chỉ sử dụng hơn 50% GPU và một lượng CPU hạn chế [3]. Việc sử dụng CPU của chúng tôi trong quá trình thử nghiệm đạt trung bình khoảng 8%.
Phần còn lại của tài liệu này cung cấp thêm thông tin chi tiết về thử nghiệm được tiến hành cho hai trường hợp sử dụng riêng biệt này của PowerEdge T360 hoặc R360 có hỗ trợ GPU.
Tổng quan về sản phẩm
PowerEdge T360 và R360 là các máy chủ mới nhất gia nhập gia đình PowerEdge . Cả hai đều là máy chủ 1 socket tiết kiệm chi phí được thiết kế cho các doanh nghiệp vừa và nhỏ có nhu cầu điện toán ngày càng tăng. Chúng có thể được triển khai trong văn phòng, vùng cận biên hoặc trong môi trường phân tích dữ liệu điển hình.
Điểm khác biệt lớn nhất giữa T360 và R360 là kiểu dáng. T360 là máy chủ dạng tháp có thể đặt gọn dưới bàn làm việc hoặc thậm chí trong tủ đựng đồ mà vẫn duy trì được độ âm thanh thân thiện với văn phòng. Mặt khác, R360 là máy chủ rack 1U truyền thống. Cả hai máy chủ đều hỗ trợ CPU Intel® Xeon® E-series mới ra mắt, 1 GPU NVIDIA A2, cũng như bộ nhớ DDR5, NVMe BOSS, cổng I/O PCIe Gen5 và khả năng quản lý từ xa mới nhất.


Hình 1. Từ trái qua phải, PowerEdge T360 và R360
Thông tin GPU NVIDIA A2
Không giống như các máy chủ thế hệ trước tương tự, PowerEdge T360 và R360 mới ra mắt gần đây hiện hỗ trợ 1 GPU đầu vào NVIDIA A2. A2 tăng tốc khối lượng công việc chuyên sâu về phương tiện truyền thông cũng như khối lượng công việc suy luận AI mới nổi. Đây là GPU có chiều rộng đơn được xếp chồng lên nhau với bộ nhớ GPU 16GB và công suất thiết kế nhiệt (TDP) có thể định cấu hình 40-60W. Đọc thêm về các tính năng và tốc độ suy luận lên tới 20 lần của GPU A2 tại đây: GPU A2 Tensor Core | NVIDIA .
Cấu hình thử nghiệm
Chúng tôi tiến hành benchmark trên một chiếc PowerEdge R360 với cấu hình như bảng bên dưới. Kết quả tương tự có thể được mong đợi đối với PowerEdge T360 với cùng cấu hình này. Chúng tôi đã thử nghiệm trong môi trường Linux Ubuntu Desktop , phiên bản 20.04.6.
Bảng 1. Cấu hình hệ thống PowerEdge R360
| Thành phần | Cấu hình |
| CPU | 1x Intel® Xeon® E-2488, 8 lõi |
| GPU | 1x NVIDIA A2 |
| Ram | 4x DIMM 32 GB, DDR5 |
| Ổ đĩa | 1 x ổ cứng SATA 2 TB |
| hệ điều hành | Ubuntu 20.04.6 |
| NIC | 2x Broadcom NetXtreme Gigabit Ethernet |
Tăng tốc khối lượng công việc kết xuất 3D
GPU đầu vào thường được sử dụng trong ngành truyền thông và giải trí để tạo mô hình và kết xuất 3D. GPU NVIDIA A2 là công cụ tăng tốc mạnh mẽ cho những khối lượng công việc này. Để làm nổi bật mức độ tăng tốc, chúng tôi đã chạy cùng một điểm chuẩn Blender OpenData trên CPU và sau đó chỉ trên GPU. Blender là một phần mềm tạo mô hình 3D mã nguồn mở phổ biến.
Điểm chuẩn đánh giá hiệu suất hiển thị của hệ thống đối với ba cảnh 3D khác nhau, chỉ trên CPU hoặc GPU. Kết quả hoặc điểm số được báo cáo dưới dạng mẫu mỗi phút. Chúng tôi đã chạy điểm chuẩn trên CPU (Intel Xeon-E2488) ba lần và sau đó trên GPU (NVIDIA A2) ba lần. Các kết quả trong Bảng 2 dưới đây thể hiện điểm trung bình của mỗi thử nghiệm trong số ba thử nghiệm.
Kết quả
So với điểm chuẩn chỉ chạy trên CPU, chúng tôi đã đạt được hiệu suất kết xuất tốt hơn tới 5 lần với cùng khối lượng công việc chạy trên GPU A2 [1]. Mặc dù chúng tôi đã đạt được hiệu suất tốt hơn gấp 4 lần cho cả ba cảnh 3D, cảnh lớp học tương ứng với kết quả tốt nhất và được minh họa trong hình bên dưới.

Hình 2. Hiệu suất kết xuất chỉ trên CPU và GPU
Với hiệu suất kết xuất tốt hơn gấp 5 lần này, chúng tôi đã tính toán hiệu suất trên mỗi đô la đối với chi phí CPU so với chi phí GPU. Đối với hiệu suất CPU, chúng tôi chia điểm kết xuất cho giá niêm yết của Dell US cho CPU E-2488. Đối với hiệu suất GPU, chúng tôi chia điểm kết xuất cho giá niêm yết của Dell tại Hoa Kỳ cho GPU A2 [2] . Khi so sánh những kết quả này, chúng tôi nhận thấy khách hàng có thể đạt được hiệu suất gấp 1,70 lần trên mỗi đô la chi cho GPU so với CPU [2].
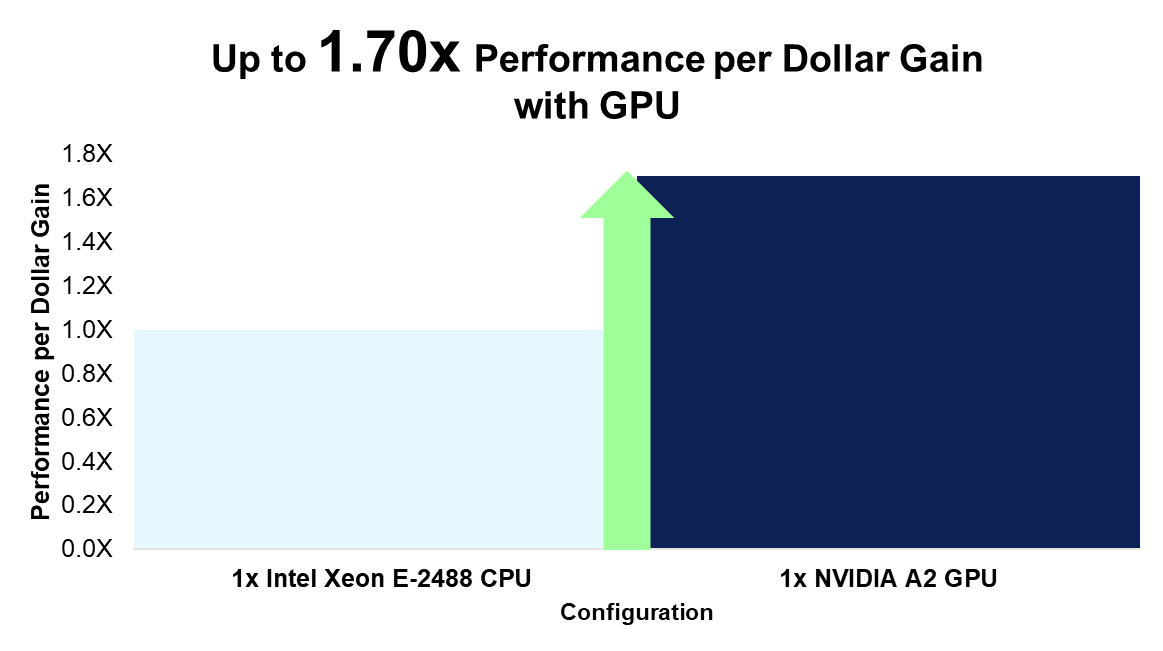
Hình 3. Hiệu suất hiển thị trên mỗi đô la tăng lên
Tiến thêm một bước phân tích nữa, chúng tôi cũng đã tính toán hiệu suất trên mỗi đô la chi cho CPU so với chi phí của cả CPU và GPU. Sự so sánh này phù hợp với những khách hàng đang đầu tư vào cả CPU Intel Xeon E-2488 và GPU NVIDIA A2 cho PowerEdge R360/T360 của họ. Mặc dù chúng tôi tính điểm hiệu suất CPU theo cách tương tự như trên nhưng giờ đây chúng tôi chia điểm kết xuất GPU cho giá niêm yết của Dell tại Hoa Kỳ cho GPU A2 + CPU E-2488. Khi so sánh những kết quả này, chúng tôi nhận thấy khách hàng có thể đạt được hiệu suất lên tới 1,27 lần trên mỗi đô la chi tiêu cho cả GPU và CPU so với chỉ CPU [2].
Nói cách khác, đầu tư vào R360 với CPU E-2488 và GPU A2 mang lại lợi tức đầu tư cao hơn cho hiệu suất kết xuất so với R360 không có GPU A2 . Điều đáng nói là CPU E-2488 là CPU cao cấp nhất và đắt nhất được cung cấp cho cả T360 và R360. Thật hợp lý khi mong đợi lợi tức đầu tư thậm chí còn cao hơn cho GPU A2 khi so sánh với cùng một hệ thống có CPU cấp thấp hơn.
Kết quả và điểm số đầy đủ được liệt kê trong bảng dưới đây.
Bảng 2. Kết quả điểm chuẩn của Blender
| Bối cảnh | Chỉ CPU, mẫu mỗi phút | GPU NVIDIA A2, số mẫu mỗi phút | Tăng từ CPU lên GPU |
| Quái vật | 98.664848 | 422.8827567 | 4,29 lần |
| Cửa hàng bán đồ cũ | 62.561726 | 268.386526 | 4,29 lần |
| Lớp học | 47.35613467 | 237.8551867 | 5,02 lần |
Hiệu suất phân tích video với NVIDIA DeepStream
Mặc dù kết xuất 3D có thể là khối lượng công việc phổ biến hơn đối với các SMB đầu tư vào GPU cơ bản, nhưng chính GPU đó cũng là công cụ tăng tốc mạnh mẽ cho khối lượng công việc phân tích video và suy luận AI cơ bản. Chúng tôi đã sử dụng DeepStream phiên bản 6.3 [3] của NVIDIA để thể hiện hiệu suất của PowerEdge R360 khi chạy ứng dụng phân tích video mẫu. DeepStream có sẵn nhiều ứng dụng mẫu và luồng đầu vào để thử nghiệm. Các tệp cấu hình nhất định cho phép bạn thay đổi số lượng luồng để chạy ứng dụng mà chúng tôi sẽ giải thích chi tiết hơn bên dưới. Luồng đầu vào có thể bao gồm từ ảnh, tệp video (có mã hóa h.264 hoặc h.265) hoặc thậm chí cả camera IP RTSP.
Để minh họa rõ hơn chức năng của DeepStream, hãy xem xét các hình ảnh bên dưới được tạo từ quá trình chạy ứng dụng mẫu DeepStream của chúng tôi. Thay vì sử dụng video mẫu được cung cấp, chúng tôi đã sử dụng video có sẵn của riêng mình về khách hàng ra vào tiệm bánh. Mô hình AI trong tình huống này có thể nhận dạng người, ô tô và xe đạp. Các hình ảnh bên dưới, được cắt bớt đầu ra để phóng to người ở máy tính tiền, cho thấy cách ứng dụng thị giác này xác định chính xác hai khách hàng này bằng hộp giới hạn và nhãn “người”.

Hình 4. Đầu ra bị cắt của ứng dụng mẫu DeepStream với video nguồn đã sửa đổi
Thay vì quay video trước, camera IP RTSP về mặt lý thuyết sẽ cho phép người dùng truyền phát và phân tích cảnh quay trực tiếp của khách hàng trong cửa hàng bán lẻ. Hãy xem blog này từ nhóm Giải pháp AI của Dell để biết hướng dẫn về cách thiết lập và chạy DeepStream với webcam 1080p để phát trực tuyến đầu ra RTSP.
Chúng tôi cũng đã thử nghiệm ứng dụng mẫu DeepStream với một trong những video do NVIDIA cung cấp chiếu cảnh ô tô, xe đạp và người đi bộ trên một con đường đông đúc. Các hình ảnh bên dưới là ảnh chụp màn hình của ứng dụng mẫu chạy với 1, 4 và 30 luồng tương ứng. Trong mỗi ô hoặc luồng, mô hình đã cho đặt các hộp giới hạn xung quanh các đối tượng được xác định.
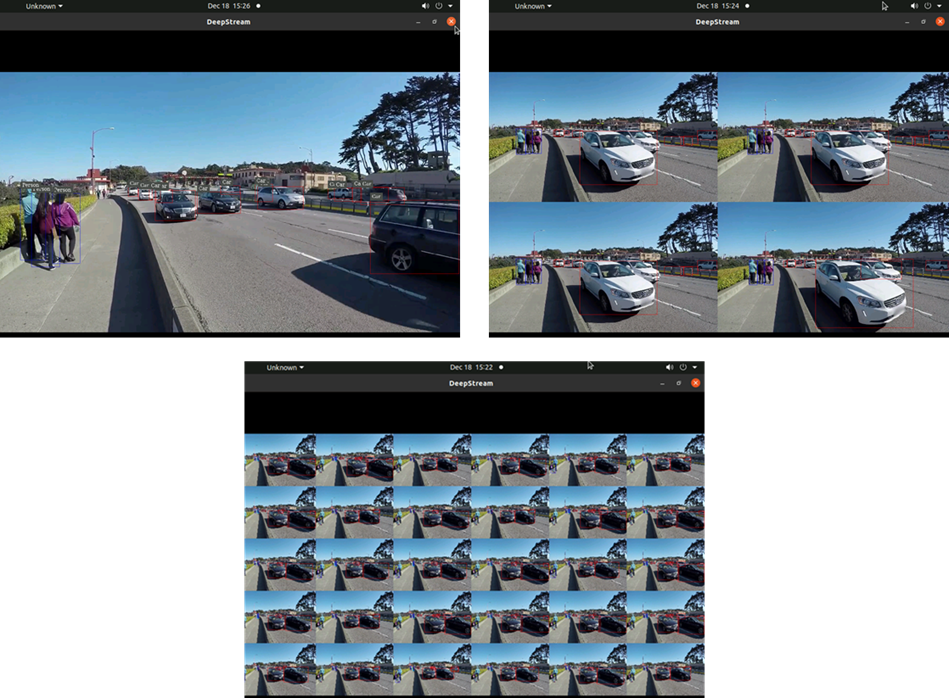
Hình 5. Đầu ra video mẫu dòng sâu với 1, 4 và 30 luồng tương ứng
Quy trình kiểm tra hiệu suất
Trong quá trình chạy một ứng dụng mẫu, NVIDIA đo hiệu suất bằng số khung hình trên giây (FPS) được xử lý. Điểm FPS được hiển thị cho mỗi luồng trong khoảng thời gian 5 giây. Để thử nghiệm, chúng tôi đã làm theo các bước trong hướng dẫn hiệu suất DeepStream 6.3 , trong đó liệt kê các sửa đổi phù hợp đối với tệp cấu hình để tối đa hóa hiệu suất. Tất cả các sửa đổi đã được thực hiện đối với tệp cấu hình source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt, được mô tả cụ thể trong “GPU trung tâm dữ liệu – phần A2” của hướng dẫn. Các màn hình xếp chồng như trong Hình 4 và 5 ở trên ảnh hưởng đến hiệu suất, vì vậy NVIDIA khuyên bạn nên tắt hiển thị/đầu ra trên màn hình khi đánh giá hiệu suất. Chúng tôi cũng làm như vậy.
Với cùng một video mẫu như trong Hình 5, NVIDIA báo cáo rằng sử dụng nguồn H.264, có thể lưu trữ 48 luồng suy luận ở tốc độ 30 FPS mỗi luồng. Để kiểm tra điều này với GPU PowerEdge R360 và A2 của chúng tôi, chúng tôi đã làm theo quy trình đo điểm chuẩn bên dưới:
- Sửa đổi tệp cấu hình ứng dụng mẫu để nhận 48 luồng đầu vào bằng cách thay đổi tham số num-source thành 48 và tham số kích thước lô trong phần luồng thành 48. [4] Điều này bổ sung cho các thay đổi cấu hình được đề xuất khác được mô tả trong hướng dẫn ở trên.
- Để ứng dụng chạy trong 10 phút [5]
- Ghi lại FPS trung bình cho mỗi luồng trong số 48 luồng khi kết thúc quá trình chạy
- Lặp lại các bước 1-3 với các luồng 40, 30, 20, 10, 5 và 1. Sửa đổi duy nhất đối với tệp cấu hình phải là cập nhật số nguồn và kích thước lô để khớp với số lượng luồng hiện đang được thử nghiệm.
Kết quả của chúng tôi được minh họa trong phần dưới đây. Chúng tôi cũng đã sử dụng các công cụ iDRAC và lệnh nvidia-smi để thu thập dữ liệu đo từ xa của hệ thống cứ 7 giây một lần trong quá trình thử nghiệm (tức là mức sử dụng CPU, tổng mức sử dụng năng lượng, mức tiêu thụ năng lượng GPU và mức sử dụng GPU). Mỗi thống kê mức sử dụng được báo cáo (chẳng hạn như mức sử dụng GPU) là mức trung bình của 100 điểm dữ liệu được thu thập trong khoảng thời gian chạy ứng dụng.
Kết quả
Hình bên dưới hiển thị FPS trung bình (đến số nguyên gần nhất) đạt được cho số lượng luồng khác nhau. Khi số lượng luồng được kiểm tra tăng lên, FPS trên mỗi luồng sẽ giảm.
Đáng chú ý nhất là chúng tôi đã đạt được hiệu suất tối đa như mong đợi của NVIDIA với PowerEdge R360; Chúng tôi đã chạy 48 luồng với trung bình 30 FPS mỗi luồng vào cuối thời gian chạy 10 phút [3]. Nói chung, 30 FPS là tốc độ được ngành chấp nhận đối với nguồn cấp dữ liệu video tiêu chuẩn như truyền hình trực tiếp.
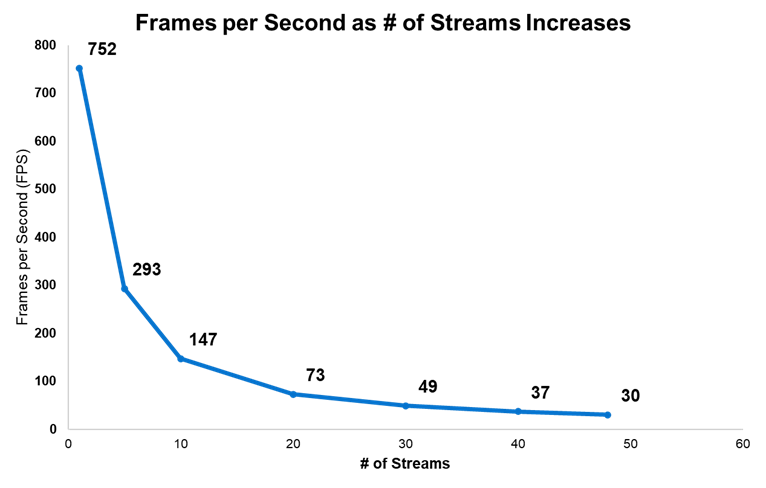
Hình 6. DeepStream FPS cho số lượng luồng khác nhau
Chúng tôi cũng nắm bắt được việc sử dụng CPU trong quá trình thử nghiệm của mình. Không có gì đáng ngạc nhiên khi mức sử dụng CPU cao nhất với 48 luồng. Tuy nhiên, đối với tất cả số luồng được thử nghiệm, mức sử dụng CPU chỉ dao động trong khoảng 2-8%. Điều này có nghĩa là hầu hết CPU của hệ thống vẫn sẵn sàng cho công việc khác trong khi chúng tôi thử nghiệm DeepStream.
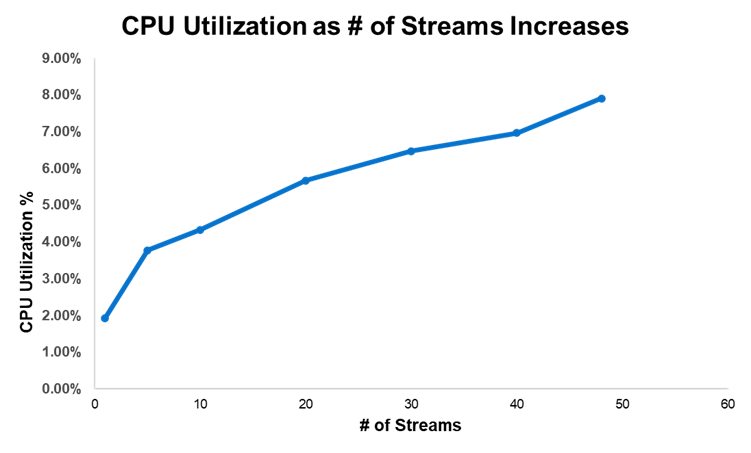
Hình 7. Việc sử dụng CPU cho số lượng luồng khác nhau
Về mức tiêu thụ điện năng, hình bên dưới hiển thị mức tiêu thụ điện năng của GPU dựa trên tổng mức sử dụng điện năng của hệ thống. Bất kể số lượng luồng, mức tiêu thụ năng lượng GPU chỉ chiếm khoảng 25-27% tổng mức sử dụng năng lượng của hệ thống.
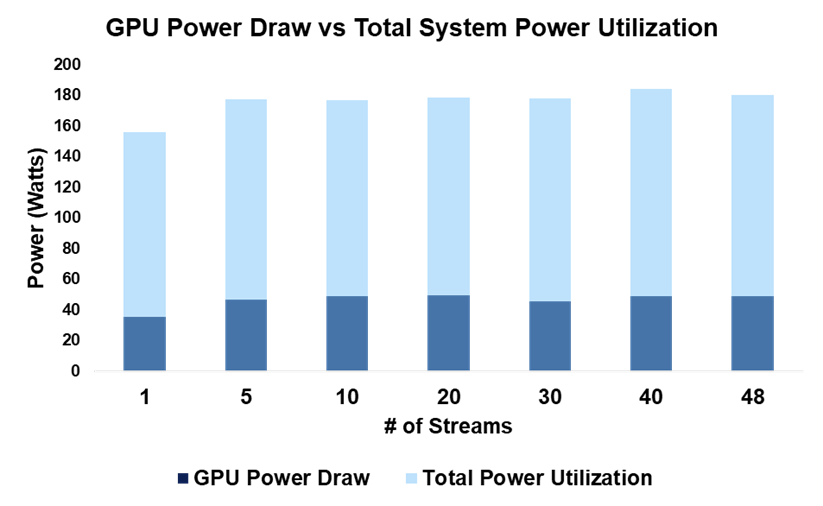
Hình 8. Mức tiêu thụ điện năng của hệ thống đối với số lượng luồng khác nhau
Cuối cùng, chúng tôi nắm bắt được mức sử dụng GPU khi số lượng luồng tăng lên. Mặc dù nó thay đổi nhiều hơn so với dữ liệu đo từ xa khác, nhưng ở số lượng luồng tối đa được thử nghiệm, mức sử dụng GPU là khoảng 50%. Chúng tôi đã đạt được những kết quả ấn tượng này mà không cần tận dụng tối đa GPU.
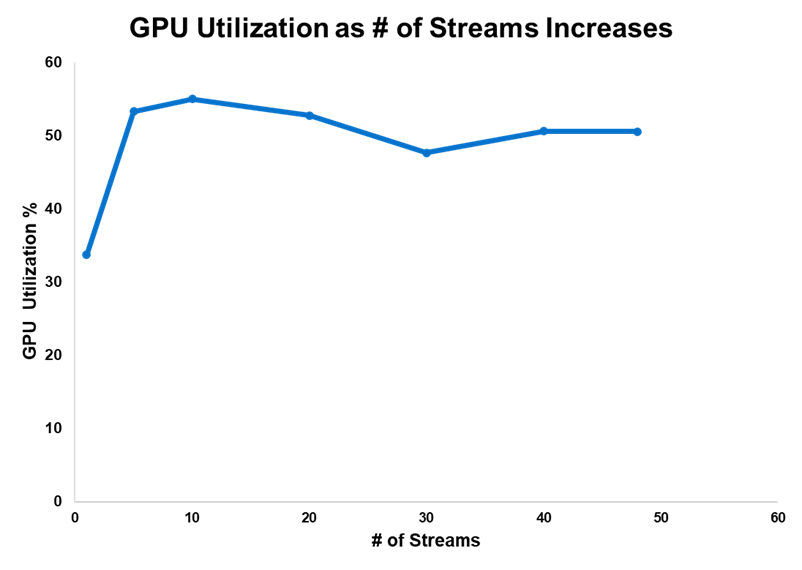
Hình 9. Việc sử dụng GPU cho số lượng luồng khác nhau
Phần kết luận
Chúng tôi vừa mới sơ lược về khả năng hoạt động của PowerEdge T360 và R360. Giữa kết xuất 3D và khối lượng công việc suy luận AI cơ bản; GPU A2 được bổ sung cho phép SMB khám phá các trường hợp sử dụng chuyên sâu về điện toán từ văn phòng đến cận biên. Nói cách khác, R360 và T360 được trang bị để mở rộng quy mô cho các doanh nghiệp khi nhu cầu điện toán tăng lên nhanh chóng và chắc chắn.
Mặc dù hỗ trợ GPU là một tính năng nổi bật của PowerEdge T360 và R360, nhưng chúng cũng tận dụng CPU Intel ® Xeon ® E-series mới ra mắt, bộ nhớ DDR5 nhanh hơn 1,4 lần, NVMe BOSS và cổng I/O PCIe Gen5. Để biết thêm thông tin về các máy chủ cấp thấp, tiết kiệm chi phí này, bạn có thể đọc về hiệu suất tuyệt vời của chúng qua nhiều tiêu chuẩn phù hợp với ngành và hiệu suất CPU tốt hơn tới 108% .


