Hadoop HDFS là gì? Đặc điểm và cấu trúc của HDFS
Th1
Công nghệ Hadoop là một công nghệ chủ chốt trong việc lưu trữ và truy cập Big Data. Hadoop còn cung cấp hệ thống phân tán tệp tin HDFS với mục đích tạo ra khoảng trống lưu trữ dữ liệu lớn cùng chi phí rẻ. Vậy Hadoop HDFS là gì? HDFS có các đặc điểm và cấu trúc như thế nào? Để hiểu rõ về vấn đề này chúng ta hãy cùng đến với những thông tin dưới đây nhé.
Định nghĩa Hadoop HDFS là gì?
Khi khối lượng dữ liệu người dùng ngày càng lớn và kích thước của các file dữ liệu vượt quá giới hạn lưu trữ thì nhu cầu phân chia dữ liệu ra các ổ cứng trên nhiều máy tính là vô cùng cần thiết. Và HDFS ra đời để hỗ xử lý vấn đề này một cách triệt để. HDFS có tên viết tắt là Hadoop Distributed File System”. Đây chính là một hệ thống lưu trữ dữ liệu được dùng bởi Hadoop. Chúng có chức năng cung cấp khả năng truy cập với hiệu suất lớn với các dữ liệu nằm trên các cụm của Hadoop.
Thường thì HDFS sử dụng trên các phần cứng với chi phí vừa phải, do các máy chủ sẽ cực dễ phát sinh các lỗi phần cứng. Bởi vậy mà HDFS được lập trình và được tạo ra nhằm chịu lỗi cao từ đó có thể giảm rủi ro cũng như giảm thiểu được tình trạng phát sinh lỗi.
Cấu trúc Hadoop phổ biến hiện nay
Hadoop gồm 4 module chính cần được quan tâm:
- Hadoop Common: Chính là các thư viện và tiện ích quan trọng của Java để các module khác sử dụng. Những thư viện này nhằm cung cấp cho hệ thống file và lớp OS trừu tượng, bên cạnh đó chúng còn chứa các mã lệnh Java để khởi động Hadoop.
- Hadoop YARN: Chính là framework để quản lý quá trình và tài nguyên của các cluster.
- Hadoop Distributed File System (HDFS): Là hệ thống file có khả năng phân tán truy cập thông lượng cao cho ứng dụng khai thác dữ liệu.
- Hadoop MapReduce: Là hệ thống dựa trên sự hoạt động của YARN dùng để xử lý song song cùng các tập dữ liệu lớn.
Hiện nay, hệ thống Hadoop ngày càng được mở rộng và được nhiều framework khác hỗ trợ như: Hive, Hbase, Pig. Dựa vào nhu cầu sử dụng mà ta sẽ áp dụng framework phù hợp để tăng hiệu quả xử lý dữ liệu của Hadoop.
Hadoop làm việc như thế nào?
Giai đoạn 1
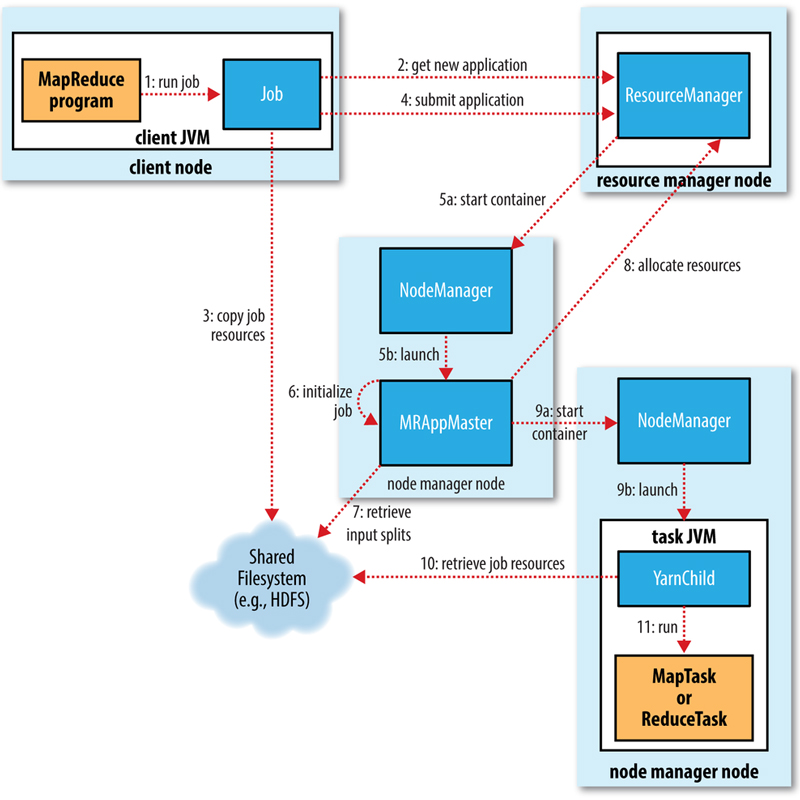
Một user hoặc một ứng dụng có thể gửi một job lên Hadoop (hadoop job client) với mục đích xử lý các thông tin cơ bản:
- Vị trí lưu (location) dữ liệu ra, vào trên hệ thống dữ liệu phân tán.
- Các java class ở định dạng jar chứa các lệnh thực thi các hàm map và reduce.
- Các lập trình cụ thể liên quan đến job thông qua các thông số truyền vào.
Giai đoạn 2
Hadoop job client submit job (file jar, file thực thi) và một số thiết lập cho JobTracker. Lúc này, master sẽ phân bổ tác vụ đến các máy slave để theo dõi và quản lý hoạt động các máy này. Bên cạnh đó chúng cung cấp thông tin về tình trạng và chẩn đoán các thông tin liên quan đến job – client.
Giai đoạn 3
TaskTracker trên các node thực hiện tác vụ MapReduce và trả về kết quả output được lưu trong hệ thống file.
Khi “chạy Hadoop” được hiểu là chạy một tập các trình nền – daemon, hoặc các chương trình được đặt trên các máy chủ khác nhau trên mạng của bạn. Những trình nền này có vai trò cụ thể, một số khác thì chỉ có ở trên một máy chủ, một số thì có ở trên nhiều máy chủ.
Các daemon gồm có:
- NameNode
- DataNode
- SecondaryNameNode
- JobTracker
- TaskTracker
Các tính năng nổi bật của HDFS
Các tính năng nổi bật của Hadoop Distributed File System (HDFS) mà người dùng cần quan tâm:
- Sao chép dữ liệu: Khi node gặp tình trạng dữ liệu bị lỗi thì hệ thống sẽ tự động lấy dữ liệu từ nơi khác trong một cụm rồi tiến hành xử lý. Điều này cho thấy HDFS có tính năng quan trọng là đảm bảo dữ liệu luôn sẵn sàng hoạt động và tránh mất mát.
- Có khả năng chịu lỗi và có độ tin cậy: Khi các tệp được chia nhỏ và nhân rộng thành nhiều bản khác nhau luôn đảm bảo khả năng chịu lỗi và độ tin cậy của dữ liệu.
- Có tính khả dụng cao: Việc sao chép dữ liệu giúp dữ liệu luôn có sẵn và được sử dụng bất kỳ lúc nào ngay cả khi NameNode hoặc DataNode bị lỗi.
- Khả năng mở rộng: Do HDFS lưu trữ dữ liệu trên các nút không giống nhau trong cụm. Vì thế khi các yêu cầu tăng lên, một cụm có thể mở rộng đến nhiều nút.
- Thông lượng cao: Với sự phân tán, các tệp tin HDFS có thể được điều chỉnh song song trên một cụm nút. Điều này giúp giảm thời gian xử lý dữ liệu và cho phép thông lượng cao.
- Vị trí dữ liệu: Thay vì chuyển phần dữ liệu lớn đến vị trí của đơn vị tính toán. HDFS cho phép sự tính toán xảy ra trên các DataNodes. Điều này có vai trò giúp làm giảm tình trạng tắc nghẽn mạng và tăng thông lượng tổng thể của toàn hệ thống.
Trên đây là tất cả thông tin cần thiết giúp bạn có thể hiểu rõ hơn về Hadoop HDFS là gì cũng như đặc điểm và cấu trúc của chúng. Hy vọng bài viết đáp ứng nhu cầu về tài liệu bạn đang tìm kiếm.


