NVIDIA trình làng GPU Blackwell B200, Switch InfiniBand Quantum-X800 Q3400, ConnectX-8 SuperNIC
Năm năm sau, sự kiện công nghệ điện toán AI nổi tiếng toàn cầu, hội nghị NVIDIA GTC thường niên, đã có sự trở lại đáng kể đối với hình thức gặp trực tiếp. Hôm nay, người sáng lập và Giám đốc điều hành của NVIDIA, Jensen Huang, đã có bài phát biểu quan trọng kéo dài hai giờ giới thiệu chip AI đột phá mới nhất – GPU Blackwell.

Trong hội nghị này, NVIDIA đã thể hiện tầm ảnh hưởng ấn tượng trong ngành bằng cách quy tụ các chuyên gia AI hàng đầu và các nhà lãnh đạo trong ngành. Sự kiện chứng kiến một lượng cử tri đi bỏ phiếu chưa từng có với hơn mười nghìn người tham dự trực tiếp.

Vào lúc 1 giờ chiều ngày 18 tháng 3 theo giờ địa phương (4 giờ sáng ngày 19 tháng 3 tại Bắc Kinh), bài phát biểu quan trọng được mong đợi nhất của GTC đã chính thức bắt đầu. Sau một bộ phim ngắn có chủ đề AI, Jensen Huang bước lên sân khấu chính với chiếc áo khoác da màu đen mang tính biểu tượng của mình, giao lưu với khán giả.
Ông bắt đầu bằng cách suy ngẫm về hành trình 30 năm của NVIDIA trong việc tăng tốc điện toán, nêu bật các cột mốc quan trọng như phát triển mô hình điện toán CUDA mang tính cách mạng, cung cấp siêu máy tính AI đầu tiên DGX cho OpenAI và sau đó chuyển trọng tâm sang AI tổng hợp một cách tự nhiên.
Sau khi công bố mối quan hệ hợp tác quan trọng với các công ty EDA hàng đầu, ông đã thảo luận về sự phát triển nhanh chóng của các mô hình AI thúc đẩy nhu cầu năng lượng tính toán tăng vọt trong đào tạo, nhấn mạnh nhu cầu về GPU lớn hơn. Ông tuyên bố rằng “điện toán tăng tốc đã đạt đến điểm tới hạn và điện toán đa năng đã mất đà”, nêu bật những tiến bộ đáng kể trong điện toán tăng tốc ở nhiều ngành khác nhau. Sau đó, hàng loạt linh kiện chủ chốt từ GPU, siêu chip cho đến siêu máy tính, hệ thống cụm nhanh chóng xuất hiện trên màn hình lớn trước khi Jensen Huang đưa ra thông báo chính: chip AI hàng đầu hoàn toàn mới – GPU Blackwell đã xuất hiện!

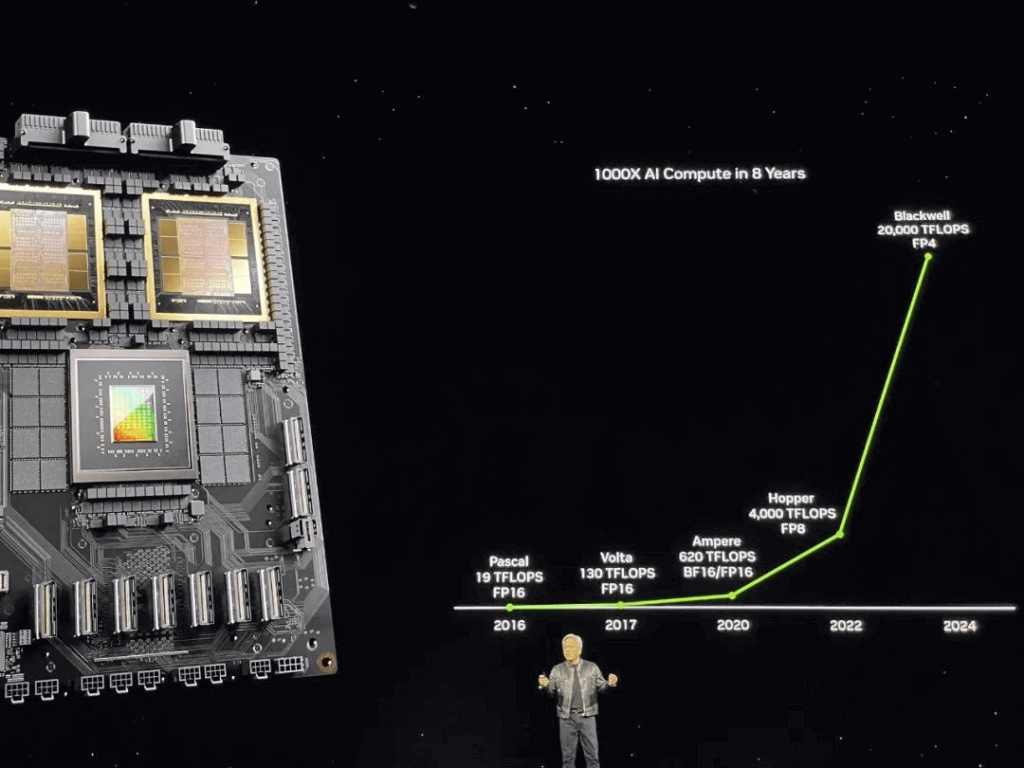
Cải tiến mới nhất này trong lĩnh vực GPU vượt trội hơn GPU Hopper tiền nhiệm cả về cấu hình và hiệu năng. Jensen Huang đã so sánh GPU Blackwell và Hopper, cho thấy kích thước lớn hơn đáng kể của Blackwell. Sau sự so sánh này, anh ấy hài hước trấn an Hopper rằng: “Không sao đâu, Hopper. Cậu giỏi lắm, cậu bé ngoan. Cô gái ngoan.” Hiệu suất của Blackwell thực sự rất đặc biệt! Cho dù đó là FP8 hay độ chính xác FP6 và FP4 mới, cùng với quy mô mô hình và băng thông HBM có thể đáp ứng – tất cả đều vượt trội so với thế hệ Hopper trước đó.

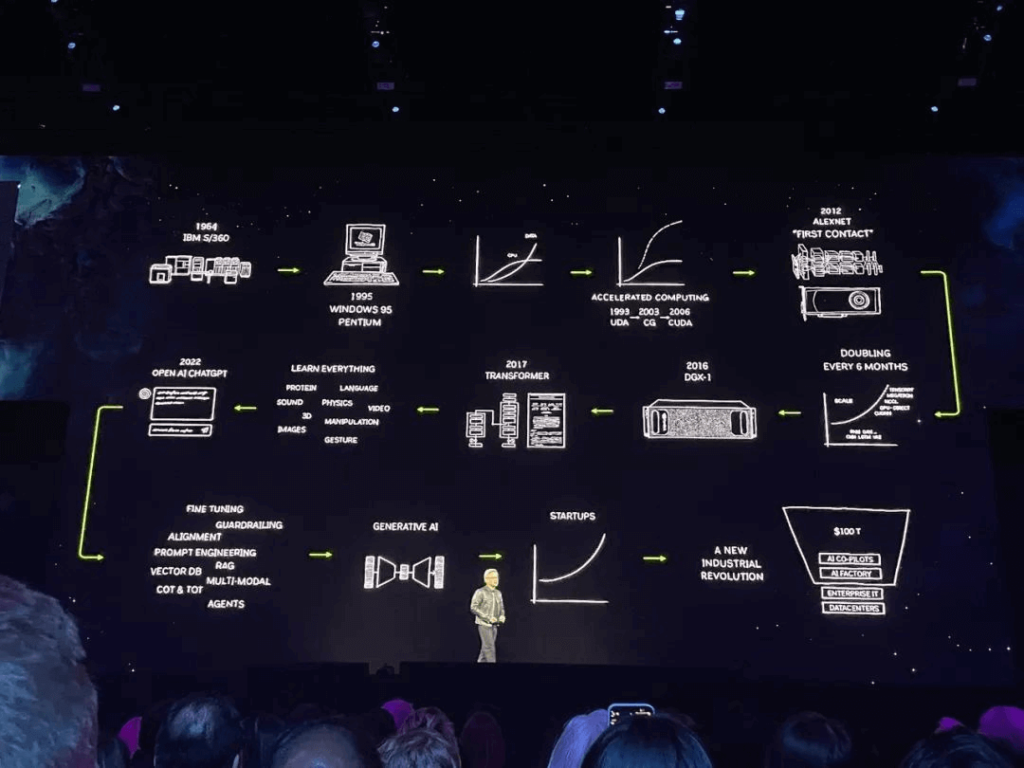
Hơn 8 năm từ kiến trúc Pascal đến kiến trúc Blackwell, NVIDIA đã tăng hiệu suất tính toán AI lên 1000 lần!
Đây mới chỉ là khởi đầu vì tham vọng thực sự của Jensen Huang nằm ở việc tạo ra cơ sở hạ tầng AI mạnh mẽ nhất có khả năng tối ưu hóa tính toán GPU ở mức nghìn tỷ thông số. Nhìn chung, NVIDIA đã công bố sáu thông báo chính tại hội nghị GTC năm nay:
- Giới thiệu GPU Blackwell: Hiệu suất đào tạo tăng 2,5 lần, hiệu suất suy luận chính xác FP4 tăng gấp 5 lần so với FP8 trước đó; nâng cấp NVLink thế hệ thứ năm với tốc độ kết nối gấp đôi tốc độ của Hopper; có thể mở rộng lên tới 576 GPU để giải quyết các tắc nghẽn giao tiếp trong các mô hình chuyên gia hỗn hợp nghìn tỷ tham số.
- Giới thiệu Kiến trúc Blackwell: Được tối ưu hóa để tính toán GPU ở mức nghìn tỷ tham số; ra mắt bộ chuyển mạch mạng dòng X800 mới với thông lượng lên tới 800Gb/s ; giới thiệu siêu chip GB200, hệ thống GB200 NVL72, hệ thống DGX B200 và siêu máy tính DGX SuperPOD AI thế hệ tiếp theo.

- Phát hành hàng chục dịch vụ AI siêu nhỏ dành cho doanh nghiệp, cung cấp một cách mới để đóng gói và phân phối phần mềm để dễ dàng triển khai các mô hình AI tùy chỉnh bằng GPU.
- Thông báo về nền tảng tính toán in thạch bản đột phá cuLitho của TSMC và Synopsys: cuLitho tăng tốc tính toán in thạch bản lên 40-60 lần bằng cách sử dụng thuật toán AI tổng quát nâng cao để cung cấp hỗ trợ đáng kể cho việc phát triển các quy trình 2nm trở lên.
- Ra mắt mô hình cơ sở robot hình người Project GR00T và máy tính robot hình người mới Jetson Thor; những nâng cấp đáng kể cho nền tảng robot Isaac thúc đẩy những tiến bộ về trí tuệ thể hiện. Jensen Huang cũng tương tác với một cặp robot NVIDIA nhỏ của Disney Research.
- Hợp tác với Apple để tích hợp nền tảng Omniverse vào Apple Vision Pro và cung cấp API Omniverse Cloud cho các công cụ phần mềm song sinh kỹ thuật số công nghiệp.
Chip AI mới xuất hiện: 20,8 tỷ bóng bán dẫn, hiệu suất đào tạo gấp 2,5 lần, hiệu suất suy luận gấp 5 lần
Bước vào kỷ nguyên mới của AI thế hệ mới, sự tăng trưởng bùng nổ về nhu cầu điện toán AI đã dẫn đến sự xuất hiện của GPU Blackwell, vượt qua GPU Hopper tiền nhiệm để trở thành tâm điểm của cuộc cạnh tranh AI. Mỗi thế hệ kiến trúc GPU NVIDIA được đặt theo tên của một nhà khoa học và kiến trúc mới, Blackwell, nhằm vinh danh David Blackwell, thành viên người Mỹ gốc Phi đầu tiên của Viện Hàn lâm Khoa học Quốc gia, đồng thời là một nhà thống kê và toán học xuất sắc. Blackwell nổi tiếng với việc đơn giản hóa các vấn đề phức tạp và những phát minh độc lập của ông như “lập trình động” và “định lý đổi mới” đã có ứng dụng rộng rãi trên nhiều lĩnh vực khoa học và kỹ thuật khác nhau.

Huang tuyên bố rằng AI thế hệ mới là công nghệ xác định thời đại này, với Blackwell là động cơ thúc đẩy cuộc cách mạng công nghiệp mới này. GPU Blackwell tự hào có sáu công nghệ cốt lõi:
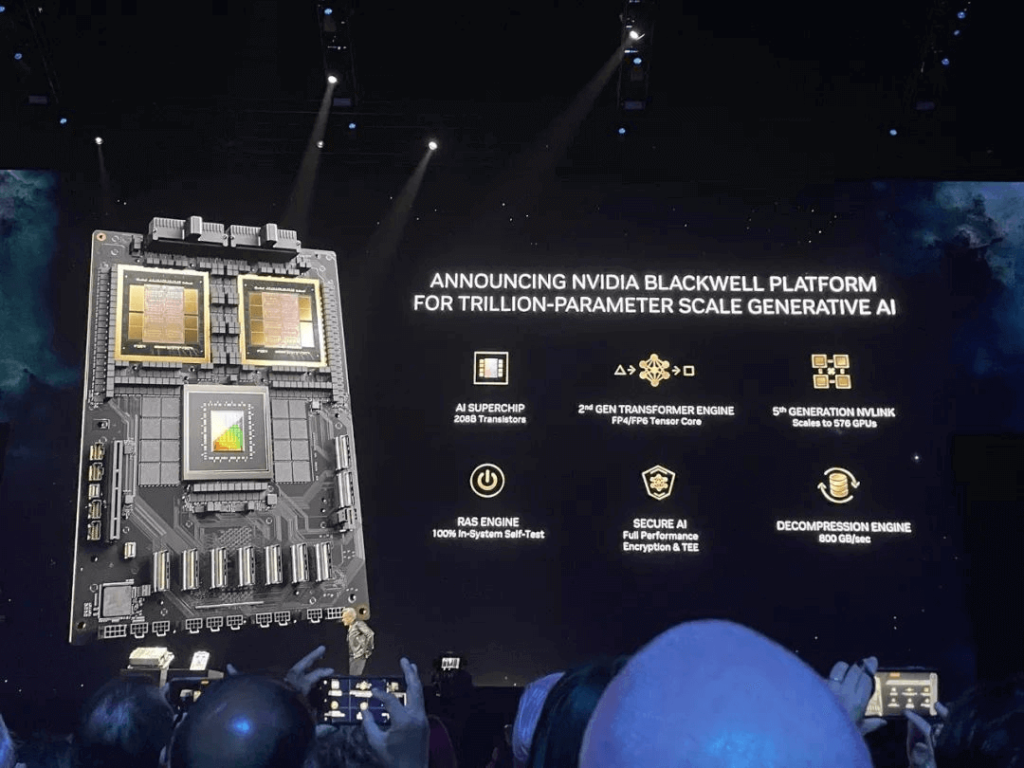
- Được mệnh danh là “Chip mạnh nhất thế giới” : tích hợp 20,8 tỷ bóng bán dẫn sử dụng quy trình TSMC 4NP tùy chỉnh, theo concept thiết kế “chiplet” với kiến trúc bộ nhớ hợp nhất + cấu hình lõi kép, kết nối hai khuôn GPU bị giới hạn bởi các mẫu in thạch bản thông qua 10TB/ Giao diện NVHyperfuse liên chip của S để tạo thành một GPU thống nhất với bộ nhớ HBM3e 192GB, băng thông bộ nhớ 8TB/s và sức mạnh đào tạo AI một thẻ lên tới 20PFLOPS.

So với thế hệ Hopper trước đây, việc Blackwell tích hợp hai die mang lại kích thước lớn hơn với thêm 12,8 tỷ bóng bán dẫn so với GPU Hopper. Ngược lại, H100 trước đó chỉ có bộ nhớ HBM3 80GB và băng thông 3,35TB/s, trong khi H200 có bộ nhớ HBM3e 141GB và băng thông 4,8TB/s.
- Công cụ biến áp thế hệ thứ hai : kết hợp hỗ trợ mở rộng quy mô micro-tensor mới và thuật toán quản lý phạm vi động tiên tiến với các khung TensorRT-LLM và NeMo Megatron để trang bị cho Blackwell khả năng suy luận AI ở độ chính xác FP4, hỗ trợ tính toán kép và quy mô mô hình trong khi vẫn duy trì độ chính xác cao cho các mô hình hỗn hợp. -người mẫu chuyên nghiệp.

Với độ chính xác FP4 mới, hiệu suất AI của GPU Blackwell đạt gấp 5 lần so với Hopper. NVIDIA chưa tiết lộ hiệu suất của lõi CUDA của mình; Thông tin chi tiết hơn về kiến trúc vẫn chưa được tiết lộ.

- NVLink thế hệ thứ năm : Để tăng tốc hiệu suất cho các mô hình nghìn tỷ thông số và chuyên gia hỗn hợp, NVLink mới cung cấp cho mỗi GPU băng thông hai chiều 1,8TB/s, hỗ trợ giao tiếp tốc độ cao liền mạch giữa tối đa 576 GPU phù hợp với ngôn ngữ lớn phức tạp các mô hình.

Một chip NVLink Switch duy nhất bao gồm 50 tỷ bóng bán dẫn sử dụng quy trình TSMC 4NP, kết nối bốn NVLink với tốc độ 1,8TB/s.

- Công cụ RAS : GPU Blackwell bao gồm một công cụ chuyên dụng đảm bảo độ tin cậy, tính khả dụng và khả năng bảo trì đồng thời kết hợp các tính năng cấp chip sử dụng bảo trì dự đoán dựa trên AI để chẩn đoán và dự đoán các vấn đề về độ tin cậy nhằm tối đa hóa thời gian hoạt động của hệ thống, nâng cao khả năng mở rộng để triển khai AI quy mô lớn chạy liên tục cho hàng tuần hoặc thậm chí hàng tháng mà không bị gián đoạn, giảm chi phí hoạt động.
- AI bảo mật : Khả năng tính toán bí mật nâng cao bảo vệ các mô hình AI và dữ liệu khách hàng mà không ảnh hưởng đến hiệu suất hỗ trợ các giao thức mã hóa giao diện cục bộ mới.
- Công cụ giải nén : Hỗ trợ các định dạng mới nhất để tăng tốc các truy vấn cơ sở dữ liệu mang lại hiệu suất cao nhất cho các nhiệm vụ phân tích dữ liệu và khoa học dữ liệu. AWS, Dell, Google, Meta, Microsoft, OpenAI, Oracle, Tesla, xAI đều sẵn sàng áp dụng các sản phẩm của Blackwell. CEO của Tesla và xAI, Musk thẳng thừng tuyên bố: “Hiện tại trong lĩnh vực AI, không có gì tốt hơn phần cứng của NVIDIA”.
Khác biệt đáng kể so với việc nhấn mạnh vào hiệu suất của một chip trong các phiên bản trước đây, dòng Blackwell tập trung nhiều hơn vào hiệu suất hệ thống tổng thể với sự phân biệt mờ nhạt trong tên mã GPU mà hầu hết được gọi chung là “GPU Blackwell”. Theo tin đồn trên thị trường trước khi phát hành, B100 có thể có giá khoảng 30.000 USD trong khi B200 có thể có giá khoảng 35.000 USD; xem xét chiến lược định giá này, trong đó giá đã tăng ít hơn 50% so với các thế hệ trước nhưng hiệu suất đào tạo đã được cải thiện gấp 2,5 lần cho thấy hiệu quả chi phí cao hơn đáng kể. Nếu giá cả vẫn tương đối ổn định với mức tăng giá khiêm tốn nhưng cải thiện đáng kể hiệu quả đào tạo; khả năng cạnh tranh thị trường của GPU dòng Blackwell sẽ rất đáng gờm.
Giới thiệu Bộ chuyển mạch mạng mới và Siêu máy tính AI được tối ưu hóa cho tính toán GPU cấp nghìn tỷ tham số
Nền tảng Blackwell, ngoài HGX B100 cơ bản, còn bao gồm Bộ chuyển mạch NVLink, nút điện toán siêu chip GB200 và bộ chuyển mạch mạng dòng X800.

Trong số này, dòng X800 là bộ chuyển mạch mạng được thiết kế mới phù hợp cho các hoạt động AI quy mô lớn, nhằm hỗ trợ các tác vụ AI tổng hợp cấp nghìn tỷ tham số. Mạng Quantum-X800 InfiniBand và Spectrum-X800 Ethernet của NVIDIA là một trong những nền tảng đầu cuối đầu tiên trên thế giới có khả năng thông lượng lên tới 800Gb/s, tự hào về khả năng băng thông trao đổi tăng gấp 5 lần so với các sản phẩm thế hệ trước. Sức mạnh tính toán của mạng đã được tăng cường gấp 9 lần thông qua công nghệ SHARP thế hệ thứ tư của NVIDIA, mang lại hiệu suất tính toán mạng là 14,4TFLOPS. Những người áp dụng sớm bao gồm Microsoft Azure, Cơ sở hạ tầng đám mây Oracle và Coreweave, cùng với những người khác.

Nền tảng Spectrum-X800 được thiết kế đặc biệt cho nhiều người thuê, cho phép tách biệt hiệu suất đối với khối lượng công việc AI của từng người thuê, từ đó tối ưu hóa hiệu suất mạng cho các dịch vụ đám mây AI tổng quát và người dùng doanh nghiệp lớn. NVIDIA cung cấp giải pháp phần mềm toàn diện bao gồm thư viện truyền thông tăng tốc mạng, bộ công cụ phát triển phần mềm và phần mềm quản lý. Siêu chip GB200 Grace Blackwell được thiết kế như một bộ xử lý cho các tác vụ AI tổng hợp có quy mô nghìn tỷ tham số. Con chip này kết nối hai GPU Blackwell với một CPU NVIDIA Grace bằng công nghệ kết nối NVLink-C2C thế hệ thứ năm tốc độ 900GB/s. Tuy nhiên, NVIDIA vẫn chưa chỉ định model chính xác của GPU Blackwell.

Huang đã giới thiệu siêu chip GB200, nhấn mạnh đây là siêu chip đầu tiên có mật độ tính toán cao như vậy trong một không gian nhỏ gọn, nhấn mạnh vào bộ nhớ được kết nối và phát triển ứng dụng hợp tác giống như một “gia đình hạnh phúc”.

Mỗi nút điện toán siêu chip GB200 có thể chứa hai siêu chip GB200. Một nút chuyển mạch NVLink duy nhất có thể hỗ trợ hai bộ chuyển mạch NVLink, đạt tổng băng thông 14,4TB/s.

Nút điện toán Blackwell bao gồm hai CPU Grace và bốn GPU Blackwell, mang lại hiệu suất AI là 80PFLOPS.

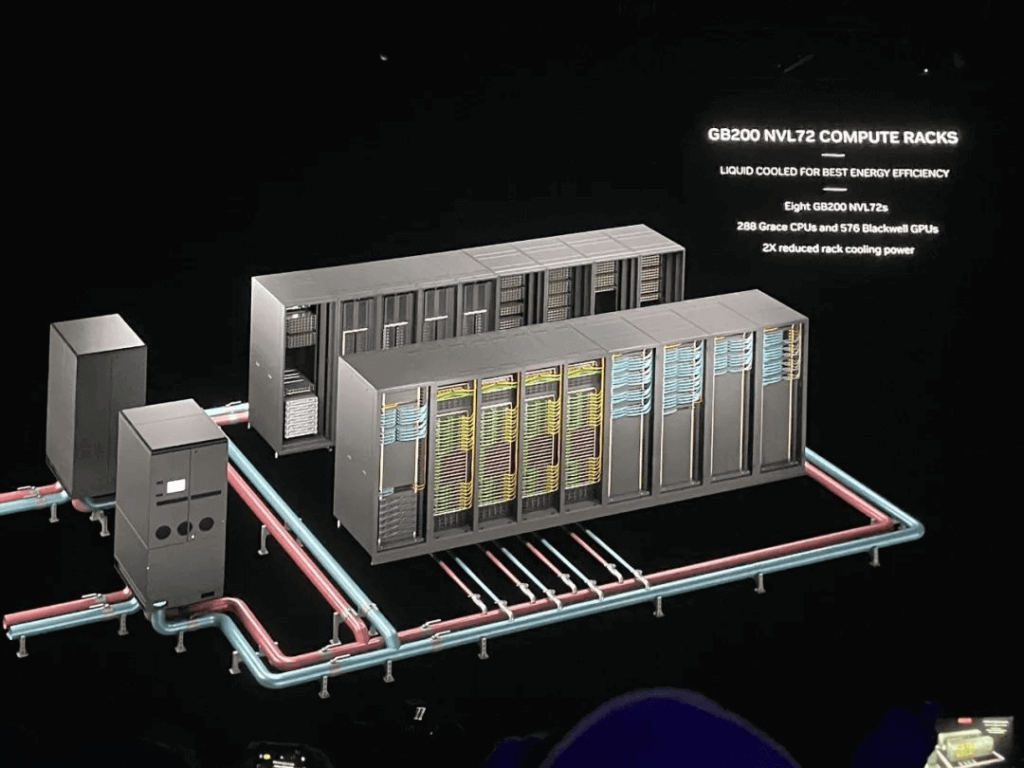
Với khả năng mạng và GPU được nâng cao, Huang đã công bố ra mắt đơn vị điện toán mới – NVIDIA GB200 NVL72 – có kiến trúc đa nút, làm mát bằng chất lỏng và hệ thống cấp giá.

GB200 NVL72 hoạt động giống như một “GPU khổng lồ”, hoạt động tương tự như GPU một card nhưng có hiệu suất đào tạo AI đạt 720PFLOPS và hiệu suất suy luận AI đạt đỉnh 1,44EFLOPS. Nó tự hào có bộ nhớ nhanh 30TB và có thể xử lý các mô hình ngôn ngữ lớn với tối đa 27 nghìn tỷ tham số, đóng vai trò là thành phần chính trong DGX SuperPOD mới nhất.

GB200 NVL72 có thể được cấu hình với siêu chip 36*GB200 (bao gồm 72*B200 GPU và 36*Grace CPU), được kết nối với nhau thông qua công nghệ NVLink thế hệ thứ năm và bao gồm cả BlueField-3 DPU.

Jensen Huang lưu ý rằng trên toàn cầu hiện chỉ có một số máy cấp EFLOPS; cỗ máy này bao gồm 600.000 bộ phận nặng 3000 pound và đại diện cho “hệ thống EFLOPS AI trong một giá đỡ duy nhất”. Ông chia sẻ rằng việc đào tạo các mẫu GPT-MoE-1.8T với H100 trước đây cần 90 ngày và khoảng 8000 GPU tiêu thụ 15MW điện năng; trong khi hiện tại sử dụng GB200 NVL72 chỉ cần 2000 GPU và công suất 4MW.

Đối với các lần chạy mô hình nghìn tỷ tham số, GB200 đã trải qua quá trình tối ưu hóa đa chiều dẫn đến tốc độ thông lượng mã thông báo GPU riêng lẻ lên tới 30 lần so với độ chính xác của H200 FP8.
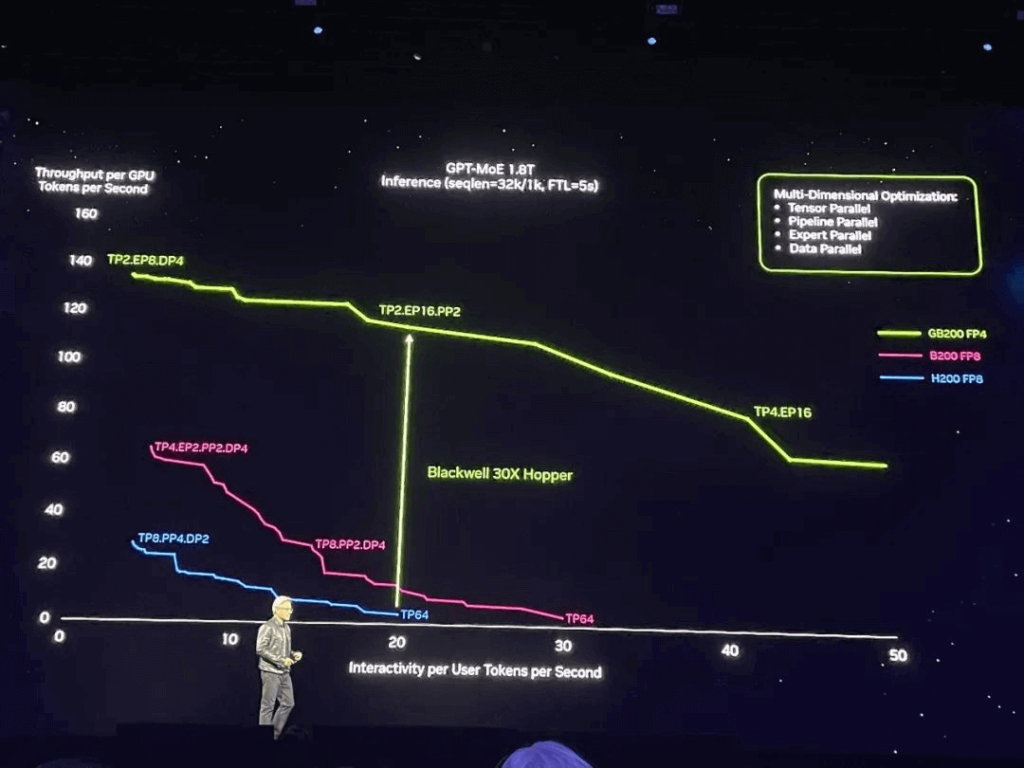
Về tác vụ suy luận mô hình ngôn ngữ lớn, GB200 NVL72 mang lại hiệu suất tăng gấp 30 lần so với cùng số lượng H100, bằng 1/25 chi phí và mức tiêu thụ điện năng của phiên bản tiền nhiệm.
Các nhà cung cấp đám mây lớn như AWS, Google Cloud, Microsoft Azure và Cơ sở hạ tầng đám mây Oracle cùng những nhà cung cấp khác hỗ trợ quyền truy cập vào GB200 NVL72. Ngoài ra, NVIDIA đã giới thiệu hệ thống DGX B200 – một nền tảng siêu máy tính AI thống nhất cho các nhiệm vụ đào tạo, tinh chỉnh và suy luận mô hình AI. Hệ thống DGX B200 đại diện cho thế hệ thứ sáu trong dòng DGX có thiết kế gắn trên giá truyền thống với khả năng làm mát bằng không khí; nó bao gồm tám GPU B200 và hai bộ xử lý Intel Xeon thế hệ thứ năm mang lại hiệu suất AI 144PFLOPS ở độ chính xác FP4 cùng với dung lượng bộ nhớ GPU lớn 1,4TB và băng thông bộ nhớ 64TB/giây cho phép tốc độ suy luận thời gian thực cho các mô hình nghìn tỷ tham số lên đến mười lăm lần nhanh hơn người tiền nhiệm của nó. Hệ thống này kết hợp mạng tiên tiến với tám NIC ConnectX-7 và hai DPU BlueField-3 cung cấp cho mỗi kết nối với băng thông lên tới 400Gb/s tạo điều kiện cho hiệu suất AI cao hơn thông qua nền tảng Quantum-2 InfiniBand và Spectrum-X Ethernet. NVIDIA cũng đã giới thiệu siêu máy tính AI cấp trung tâm dữ liệu thế hệ tiếp theo – DGX SuperPOD sử dụng hệ thống DGX GB200 có khả năng xử lý các mô hình nghìn tỷ tham số, đảm bảo hoạt động liên tục cho khối lượng công việc suy luận và đào tạo AI tổng hợp quy mô lớn. Được xây dựng từ tám hệ thống DGX GB200 trở lên, DGX SuperPOD thế hệ mới này có kiến trúc mở rộng cấp giá làm mát bằng chất lỏng hiệu quả mang lại sức mạnh tính toán AI là 11,5EFLOPS ở độ chính xác FP4 cùng với bộ nhớ lưu trữ nhanh 240TB có thể mở rộng hơn nữa thông qua giá đỡ- cải tiến cấp độ. Mỗi hệ thống DGX GB200 chứa 36 siêu chip GB200. So với các đơn vị H100 chạy các nhiệm vụ suy luận mô hình ngôn ngữ lớn, siêu chip GB200 mang lại hiệu suất tăng gấp 45 lần.
Huang hình dung các trung tâm dữ liệu là “nhà máy AI” trong tương lai, với toàn bộ ngành đang chuẩn bị cho những tiến bộ của Blackwell.

Ra mắt hàng chục dịch vụ vi mô AI sáng tạo cấp doanh nghiệp để tùy chỉnh và triển khai các phi công phụ
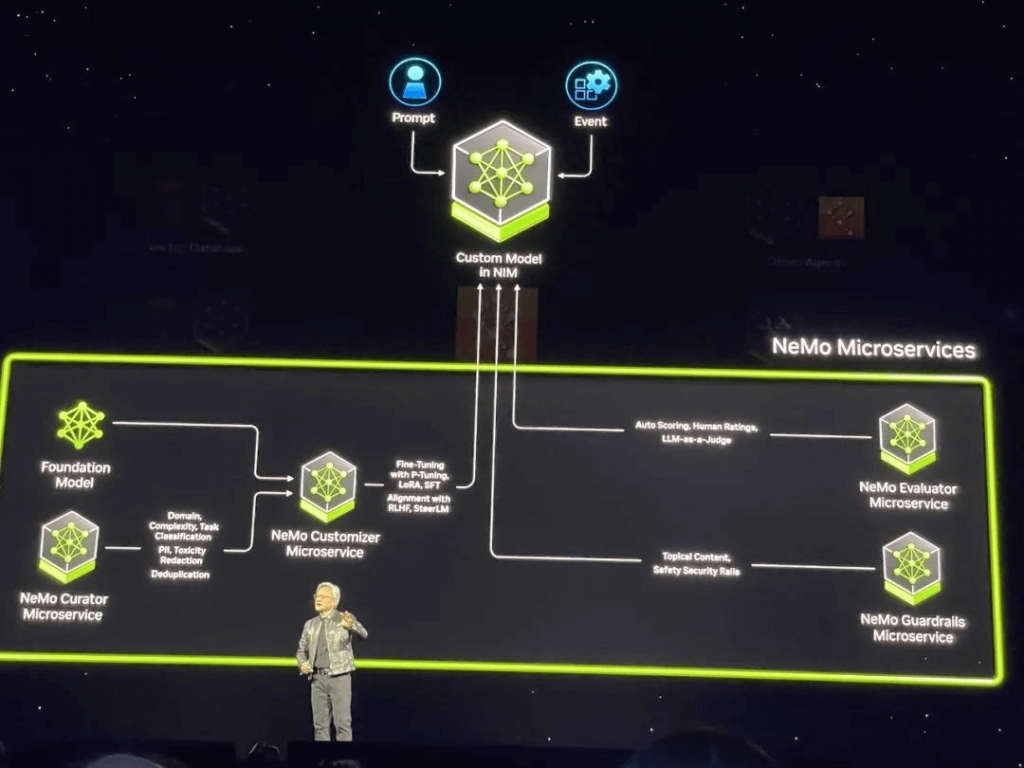
NVIDIA tiếp tục mở rộng các lợi thế được xây dựng trên CUDA và hệ sinh thái AI tổng quát bằng cách giới thiệu hàng chục vi dịch vụ AI tổng hợp cấp doanh nghiệp. Các dịch vụ này cho phép các nhà phát triển tạo và triển khai AI Copilots tổng hợp trên các bản cài đặt GPU NVIDIA CUDA.
Huang tuyên bố rằng AI tổng quát đang thay đổi cách lập trình ứng dụng, chuyển từ viết phần mềm sang lắp ráp các mô hình AI, chỉ định nhiệm vụ, cung cấp ví dụ về sản phẩm công việc, xem xét kế hoạch và kết quả trung gian. NVIDIA NIM đóng vai trò là tài liệu tham khảo cho các dịch vụ vi mô suy luận của NVIDIA, được xây dựng từ các thư viện điện toán tăng tốc và mô hình AI tổng hợp của NVIDIA. Các vi dịch vụ này hỗ trợ các API tiêu chuẩn ngành, hoạt động trên các bản cài đặt CUDA quy mô lớn của NVIDIA và được tối ưu hóa cho các GPU mới.
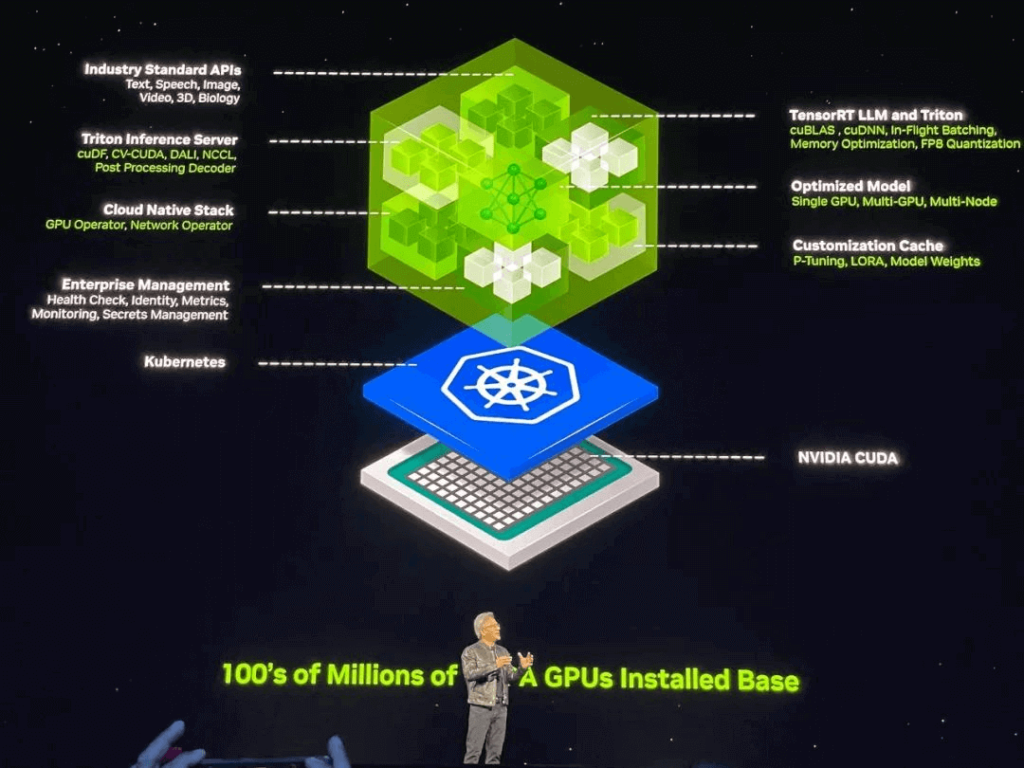
Các doanh nghiệp có thể sử dụng các dịch vụ vi mô này để tạo và triển khai các ứng dụng tùy chỉnh trên nền tảng của mình trong khi vẫn giữ được quyền sở hữu và kiểm soát hoàn toàn đối với tài sản trí tuệ của mình. Các dịch vụ vi mô NIM cung cấp các bộ chứa AI sản xuất dựng sẵn được hỗ trợ bởi phần mềm suy luận của NVIDIA, cho phép các nhà phát triển giảm thời gian triển khai từ vài tuần xuống còn vài phút. Các dịch vụ vi mô NIM có thể triển khai các mô hình từ NVIDIA, AI21, Adept, Cohere, Getty Images và Shutterstock, cũng như các mô hình mở từ Google, Hugging Face, Meta, Microsoft, Mistral AI và Stability AI.
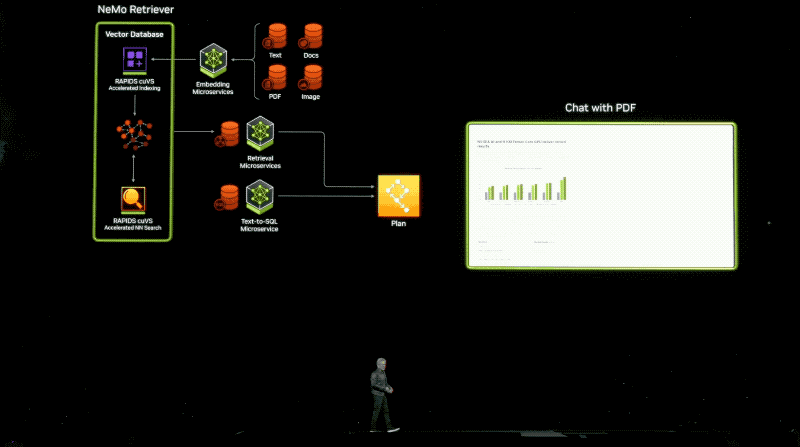
Người dùng sẽ có quyền truy cập vào các dịch vụ vi mô NIM từ Amazon SageMaker, Google Kubernetes Engine và Microsoft Azure AI, được tích hợp với các khung AI phổ biến như Deepset, LangChain và LlamaIndex. Để tăng tốc các ứng dụng AI, doanh nghiệp có thể tận dụng các vi dịch vụ CUDA-X bao gồm NVIDIA Riva cho AI dịch thuật và giọng nói tùy chỉnh, NVIDIA cuOpt để tối ưu hóa đường dẫn, NVIDIA Earth-2 để mô phỏng thời tiết và khí hậu có độ phân giải cao. Một loạt vi dịch vụ NVIDIA NeMo để phát triển mô hình tùy chỉnh sẽ sớm được phát hành.
Các nhà phát triển có thể tự do dùng thử các dịch vụ vi mô của NVIDIA tại ai.nvidia.com. Các doanh nghiệp có thể triển khai các dịch vụ vi mô NIM ở cấp độ sản xuất bằng cách sử dụng nền tảng AI Enterprise 5.0 của NVIDIA.
Thúc đẩy các thuật toán AI sáng tạo: Hợp tác với những công ty hàng đầu trong ngành bán dẫn để khơi dậy một cuộc cách mạng mới trong máy tính quang khắc
Tại hội nghị GTC năm ngoái, NVIDIA đã tiết lộ một bước phát triển mang tính đột phá sau 4 năm nghiên cứu bí mật nhắm vào ngành sản xuất chất bán dẫn: tận dụng thư viện máy tính quang khắc mang tính cách mạng cuLitho để tăng tốc tính toán quang khắc lên 40-60 lần, vượt qua giới hạn vật lý là sản xuất 2nm trở lên chip tiên tiến. Các cộng tác viên trong dự án này là những người chơi chủ chốt trong ngành bán dẫn – gã khổng lồ chip AI toàn cầu NVIDIA, công ty đúc bán dẫn hàng đầu TSMC và gã khổng lồ EDA hàng đầu Synopsys.

Kỹ thuật in thạch bản tính toán là nền tảng cho sản xuất chip. Ngày nay, dựa trên các quy trình được tăng tốc của cuLitho, tốc độ quy trình làm việc đã được tăng gấp đôi thông qua các thuật toán AI tổng quát. Cụ thể, nhiều thay đổi trong quy trình chế tạo tấm bán dẫn yêu cầu Hiệu chỉnh tiệm cận quang học (OPC), làm tăng độ phức tạp tính toán và gây ra tắc nghẽn trong quá trình phát triển. Khả năng tính toán tăng tốc và AI tổng quát của cuLitho có thể giảm bớt những vấn đề này. Việc áp dụng AI tổng quát có thể tạo ra các giải pháp hoặc phương pháp tiếp cận mặt nạ gần như hoàn hảo để giải quyết các vấn đề nhiễu xạ ánh sáng trước khi tạo ra mặt nạ cuối cùng thông qua các phương pháp nghiêm ngặt về mặt vật lý truyền thống – do đó tăng tốc toàn bộ quy trình OPC lên gấp 2 lần. Trong các quy trình sản xuất chip, in thạch bản tính toán là khối lượng công việc nặng nhất tiêu tốn hàng tỷ giờ mỗi năm trên CPU. So với các phương pháp dựa trên CPU, tính toán quang khắc được tăng tốc bằng GPU của cuLitho giúp tăng cường đáng kể quy trình sản xuất chip. Bằng cách tăng tốc tính toán, 350 hệ thống NVIDIA H100 có thể thay thế 40.000 hệ thống CPU giúp tăng đáng kể tốc độ thông lượng và tăng tốc sản xuất đồng thời giảm chi phí, yêu cầu về không gian và mức tiêu thụ điện năng. Chủ tịch TSMC Wei Zhejia cho biết: “Chúng tôi đang triển khai NVIDIA cuLitho tại TSMC, nhấn mạnh bước nhảy vọt về hiệu suất đáng kể đạt được thông qua việc tích hợp tính toán tăng tốc GPU vào quy trình làm việc của TSMC. Khi thử nghiệm cuLitho trên quy trình làm việc chung giữa hai công ty, họ đã đạt được mức tăng tốc 45 lần trong các quy trình đường cong và cải thiện gần 60 lần trong các quy trình truyền thống ở Manhattan.
Giới thiệu Mô hình và máy tính cơ sở robot hình người mới: Cập nhật chính về nền tảng robot Isaac
Ngoài AI sáng tạo, NVIDIA cũng lạc quan về trí thông minh thể hiện và đã công bố mô hình cơ sở phổ quát về robot hình người Project GR00T và máy tính robot hình người mới Jetson Thor dựa trên Thor SoC. Jensen Huang cho biết: “Phát triển mô hình cơ sở robot hình người phổ quát là một trong những chủ đề thú vị nhất trong lĩnh vực AI hiện nay”. Robot được hỗ trợ bởi GR00T có thể hiểu ngôn ngữ tự nhiên, bắt chước khả năng phối hợp học tập nhanh chóng, tính linh hoạt và các kỹ năng khác bằng cách quan sát hành vi của con người để thích ứng và tương tác với thế giới thực. Huang Renxun đã chứng minh nhiều robot như vậy có thể hoàn thành nhiều nhiệm vụ khác nhau như thế nào.
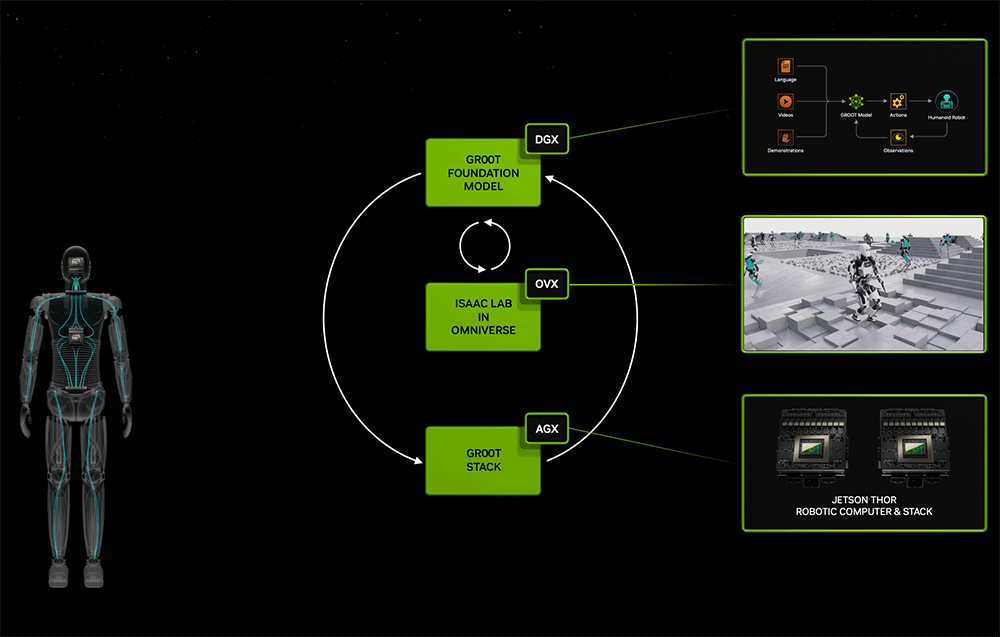
Jetson Thor có kiến trúc mô-đun được tối ưu hóa về hiệu suất, mức tiêu thụ điện năng và kích thước. SoC này bao gồm GPU Blackwell thế hệ tiếp theo với công cụ Transformer để chạy các mô hình AI tạo đa phương thức như GR00T. NVIDIA đang phát triển nền tảng AI toàn diện cho các công ty robot hình người hàng đầu như 1X, Agility Robotics, Apptronik, Boston Dynamics, Fig AI, Fourier Intelligence, Sanctuary AI, Unitree Robotics và XPENG Robotics.
Ngoài ra, NVIDIA đã thực hiện các nâng cấp đáng kể cho nền tảng robot Isaac, bao gồm các mô hình cơ sở AI tổng quát, công cụ mô phỏng và cơ sở hạ tầng quy trình làm việc AI. Những tính năng mới này sẽ được triển khai trong quý tiếp theo. NVIDIA cũng đã phát hành một loạt mô hình robot, thư viện và phần cứng tham chiếu được đào tạo trước như Isaac Manipulator cho cánh tay robot với tính linh hoạt và khả năng AI mô-đun, cùng với một loạt mô hình cơ sở và thư viện tăng tốc GPU như Isaac Perceptor cung cấp các tính năng nâng cao như thiết lập nhiều camera, tái tạo 3D và nhận biết chiều sâu.
Nền tảng Omniverse Phát triển mới nhất: Tiến tới Apple Vision Pro, Giới thiệu API đám mây
NVIDIA đã công bố việc tích hợp nền tảng Omniverse với Apple Vision Pro.

Nhắm mục tiêu vào các ứng dụng song sinh kỹ thuật số công nghiệp, NVIDIA sẽ cung cấp Omniverse Cloud dưới dạng API. Các nhà phát triển có thể sử dụng API này để truyền nội dung song sinh kỹ thuật số công nghiệp tương tác tới tai nghe VR.
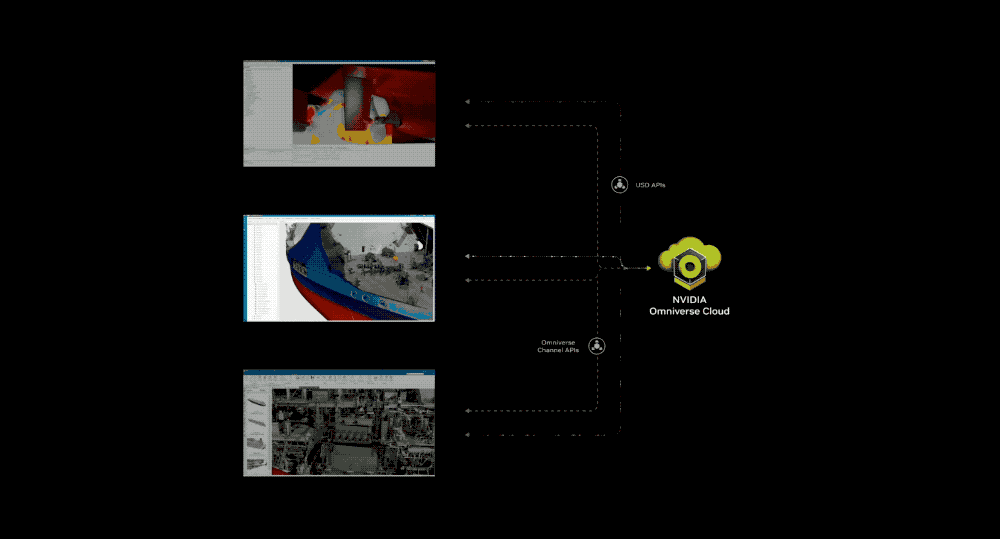
Bằng cách tận dụng API, các nhà phát triển có thể dễ dàng tích hợp trực tiếp công nghệ cốt lõi của Omniverse vào các ứng dụng phần mềm tự động hóa và thiết kế song sinh kỹ thuật số hiện có hoặc vào quy trình mô phỏng để thử nghiệm và xác nhận các máy tự động như robot hoặc ô tô tự lái. Jensen Huang tin rằng tất cả các sản phẩm được sản xuất sẽ có bản sao kỹ thuật số và Omniverse là một hệ điều hành có thể xây dựng và vận hành các bản sao kỹ thuật số thực tế về mặt vật lý. Ông tin rằng, “Omniverse và AI tổng quát đều là những công nghệ cơ bản cần thiết để số hóa thị trường công nghiệp nặng trị giá lên tới 50 nghìn tỷ USD”.
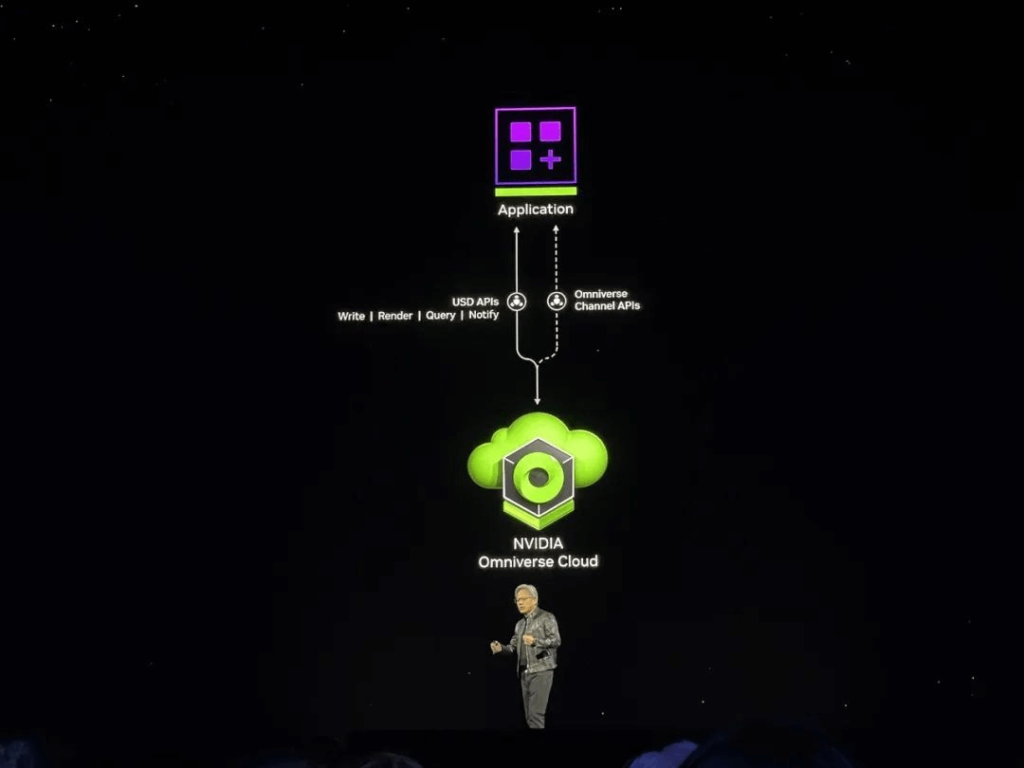
Năm API Omniverse Cloud mới có thể được sử dụng riêng lẻ hoặc kết hợp: USD Render (tạo kết xuất RTX theo dõi tia đầy đủ cho dữ liệu OpenUSD), USD Write (cho phép người dùng sửa đổi và tương tác với dữ liệu OpenUSD), USD Query (hỗ trợ truy vấn cảnh và cảnh tương tác), USD Notify (theo dõi các thay đổi của USD và cung cấp thông tin cập nhật) và Kênh Omniverse (kết nối người dùng, công cụ và thế giới để cộng tác giữa các cảnh).
API đám mây Omniverse sẽ có sẵn trên Microsoft Azure vào cuối năm nay dưới dạng API tự lưu trữ trên GPU NVIDIA A10 hoặc dưới dạng dịch vụ lưu trữ được triển khai trên NVIDIA OVX.
Kết luận: Sự kiện chính đã kết thúc nhưng chương trình vẫn phải tiếp tục
Ngoài những thông báo quan trọng được đề cập ở trên, Huang còn chia sẻ những phát triển tiếp theo trong bài phát biểu của mình: NVIDIA đã ra mắt nền tảng đám mây nghiên cứu 6G được thúc đẩy bởi Generative AI và Omniverse để thúc đẩy phát triển công nghệ truyền thông không dây trong lĩnh vực viễn thông. Nền tảng đám mây kép kỹ thuật số khí hậu Earth-2 của NVIDIA hiện có sẵn cho các mô phỏng tương tác có độ phân giải cao nhằm đẩy nhanh quá trình dự báo khí hậu và thời tiết. Ông tin rằng tác động lớn nhất của AI sẽ là trong lĩnh vực chăm sóc sức khỏe. NVIDIA hiện đang hợp tác với các công ty hệ thống hình ảnh, nhà sản xuất trình tự gen và các công ty robot phẫu thuật hàng đầu trong khi giới thiệu một loại phần mềm sinh học mới.

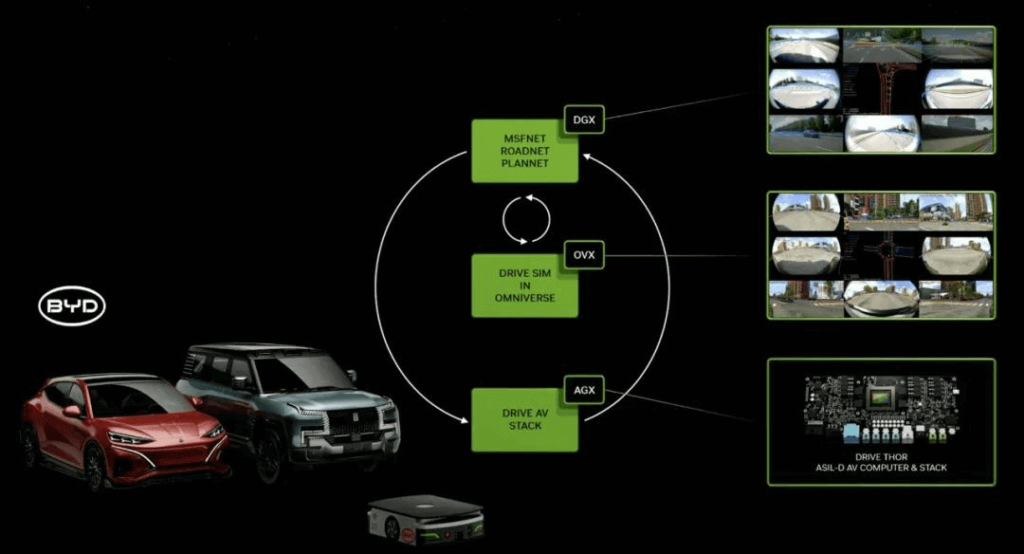
Trong ngành công nghiệp ô tô, BYD, công ty lái xe tự hành lớn nhất thế giới, sẽ trang bị cho các phương tiện điện tương lai của mình bộ xử lý xe tự hành (AV) thế hệ tiếp theo của NVIDIA DRIVE Thor dựa trên kiến trúc Blackwell. DRIVE Thor dự kiến sẽ bắt đầu sản xuất hàng loạt vào đầu năm tới với hiệu suất đạt tới 1000 TFLOPS.
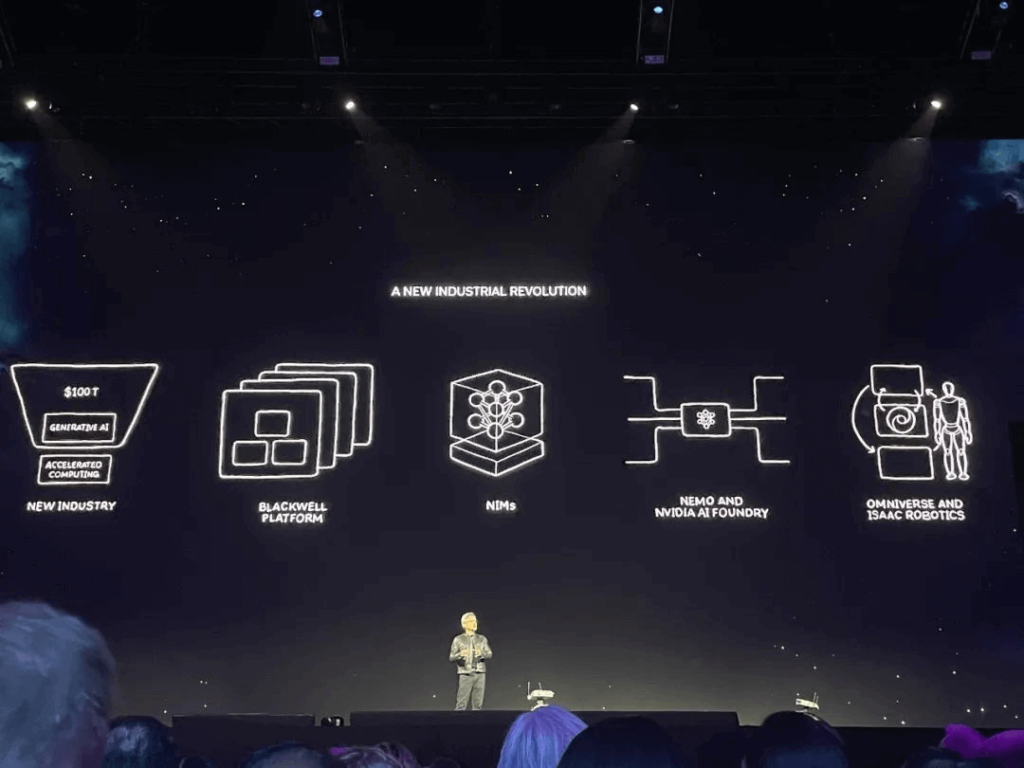
Huang cho biết: “Bản chất của NVIDIA nằm ở sự giao thoa giữa đồ họa máy tính, vật lý và trí tuệ nhân tạo”. Khi kết thúc bài phát biểu, ông đã nêu ra năm điểm chính: Công nghiệp mới, Nền tảng Blackwell, NIM, NEMO và NVIDIA AI Foundry, Omniverse và Isaac Robotics.
Hôm nay đánh dấu một cột mốc quan trọng khác trong đó NVIDIA vượt qua ranh giới của phần cứng và phần mềm AI đồng thời giới thiệu bữa tiệc xung quanh các công nghệ tiên tiến như AI, mô hình lớn, metaverse, robot, lái xe tự động, chăm sóc sức khỏe và điện toán lượng tử.
Bài phát biểu quan trọng của Jensen Huang chắc chắn là điểm nổi bật của hội nghị GTC, nhưng sự phấn khích chỉ mới bắt đầu đối với cả những người tham dự tại chỗ và từ xa!
Hơn 1000 phiên thảo luận về những tiến bộ mới nhất của NVIDIA và các chủ đề nóng về công nghệ tiên tiến sẽ diễn ra thông qua các bài phát biểu, buổi đào tạo và thảo luận bàn tròn. Nhiều người tham dự bày tỏ sự thất vọng khi không thể tham dự tất cả các phiên do hạn chế về thời gian nhưng thừa nhận nền tảng GTC 2024 cung cấp để trao đổi kỹ thuật trong ngành AI. Việc phát hành các sản phẩm mới trong giai đoạn này và chia sẻ công nghệ dự kiến sẽ có tác động tích cực đến hoạt động nghiên cứu học thuật và các chuỗi ngành liên quan. Đang chờ khám phá sâu hơn về các chi tiết kỹ thuật khác của kiến trúc Blackwell mới.


